Hi there,
I found some issues related with images.
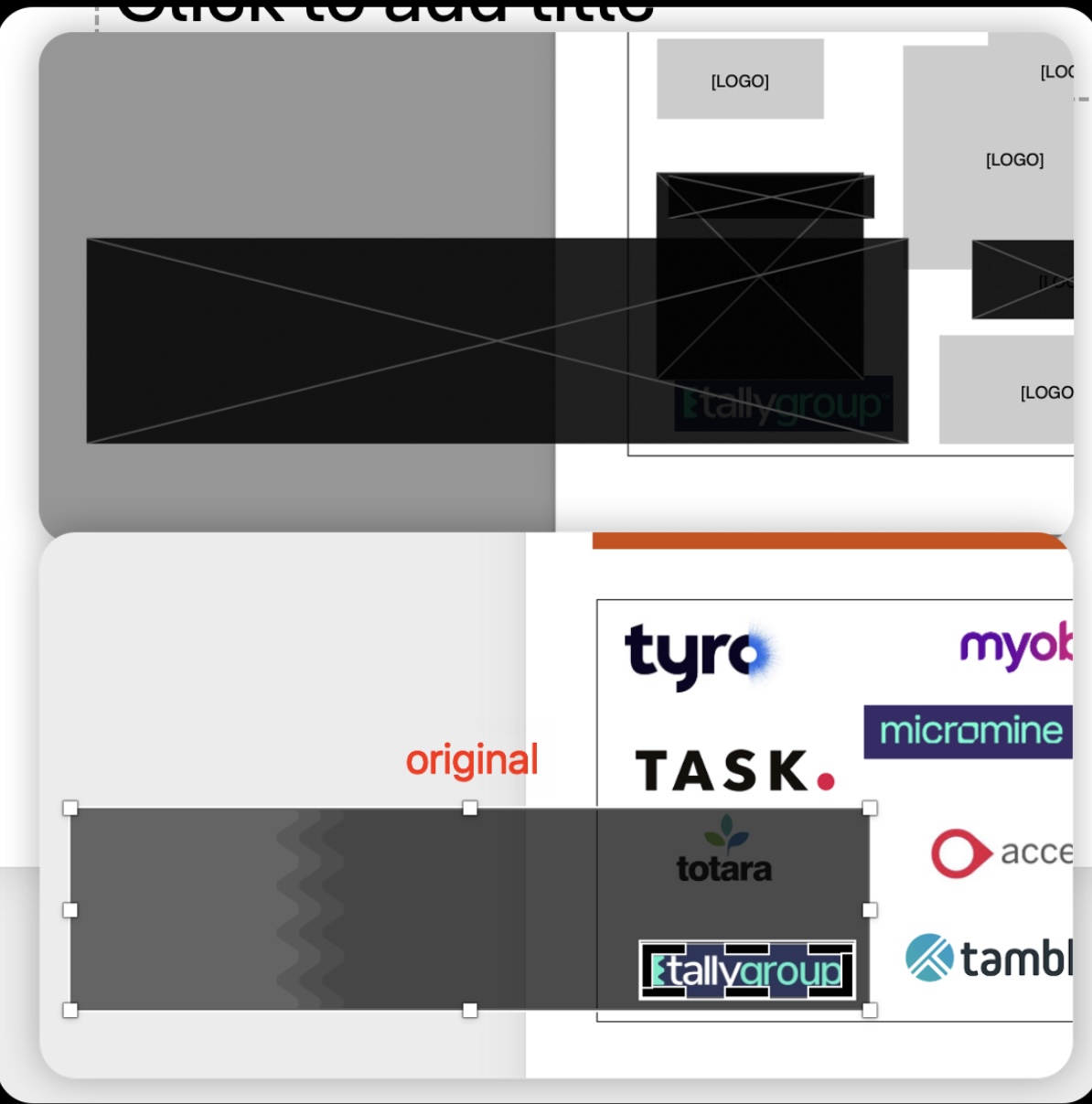
For Page 1, I can get this image using get_images(full=True). However, this is a cropped image. While I’m trying to redact it, it will redact the original image while I just want to redact the visualized part. So my question for this would be: Is there any way that I can get the bbox for the visualized part?
For Page 2, these images cannot be extracted using get_images(). I can get most of them (see redacted ones) using get_drawings and select the “clip” type, but the issues are:
While using get_drawings method, I will get a clip for the whole page as well. How can I justify if a clip is for an image, or for the whole page.
I still cannot extract the Reckon image.
The SABIO one is extracted separately, is there anyway that I can extarct it as a whole?
Thx!
test 1.pdf (230.9 KB)
I had a quick look at your first issue regarding what I think might be an image mask. Looking here: Images - PyMuPDF documentation I tried this:
import pymupdf
doc = pymupdf.open("test 1.pdf") # open a document
for page_index in range(len(doc)): # iterate over pdf pages
page = doc[page_index] # get the page
image_list = page.get_images()
# print the number of images found on the page
if image_list:
print(f"Found {len(image_list)} images on page {page_index}")
else:
print("No images found on page", page_index)
for image_index, img in enumerate(image_list, start=1):
xref = img[0] # get the XREF of the image
smask = img[1]
print(xref)
print(smask)
if smask > 0:
print("consider mask!")
pix1 = pymupdf.Pixmap(doc.extract_image(xref)["image"]) # (1) pixmap of image w/o alpha
mask = pymupdf.Pixmap(doc.extract_image(smask)["image"]) # (2) mask pixmap
pix = pymupdf.Pixmap(pix1, mask) # (3) copy of pix1, image mask added
else:
pix = pymupdf.Pixmap(doc, xref) # create a Pixmap
if pix.n - pix.alpha > 3: # CMYK: convert to RGB first
pix = pymupdf.Pixmap(pymupdf.csRGB, pix)
pix.save("_page_%s-image_%s.png" % (page_index, image_index))
pix = None
But unfortunately it didn’t seem to work. It looked to me like a different image had the mask on page 1 and not the one I was expecting?